future
Fast processing of OLAP workloads.
OLAP 级数数据处理能力
Integration with MapReduce, Spark and other Hadoop ecosystem components.
可集成大数据常用组建(MR,spark,hive,impala,…)
Tight integration with Apache Impala, making it a good, mutable alternative to using HDFS with Apache Parquet.
对impala的完全支持,可作为HDFS存储parquet方案的替代
Strong but flexible consistency model, allowing you to choose consistency requirements on a per-request basis, including the option for strict-serializable consistency.
一致性
Strong performance for running sequential and random workloads simultaneously.
强悍的并行顺序和随机的工作负载
Easy to administer and manage.
易维护
High availability.
高可用
Structured data model.
机构化数据模型
Kudu Impala 集成使用特性
- CREATE/ALTER/DROP TABLE
- INSERT
- UPDATE/DELETE
- 表名称变更
- 主键列修改
- 重命名,增加,删除 非主键列
- 添加删除range分区
Kudu 表设计
列尽量使用明确的类型,不要单一string类型
kudu 对字段有存储优化,无脑string导致kudu存储优化无效
主键
- 主键必须在建标时指定,可以是一个字段,也可以是多个字段组合
单一字段时不适合将主键字段设计得过大,否则批量复制表时导致插入删除数据时性能降低(主键缓存过大,磁盘询盘频繁)
- 主键字段中不能有空字符串,布尔,浮点型类型等
- 主键必须在建标时指定,可以是一个字段,也可以是多个字段组合
分区
kudu的 tablet是数据行在分区中存储的位置(tablet与partition一一对应)
kudu 没有默认分区,如果不指定就会写到一个tablet中
建标必须指定分区,否则表性能无法保证
hash 分区
通过指定一个或多个字段进行hash分桶,判断数据分区位置(默认情况下,使用 PARTITION BY HASH 时,整个主键是散列的)
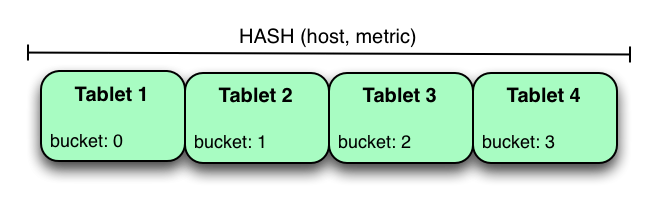
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23create table kudu_test.real_time_sales_temporary_kuduc ( sdt String, shopId String, updateTime String, serialId String, sheetId String, goodsId String, key_by String, timeFrame String, regionId String, regionName String, shopName String, serviceRegionId String, serviceRegionName String, shopBelongId String, shopBelongName String, primary key(sdt,shopId,updatetime,serialId,sheetid) ) PARTITION by hash(sdt,shopId) partitions 32 COMMENT '销售流水表C' STORED AS kudu;范围分区
通过指定数据字段的值范围,判断数据分区位置
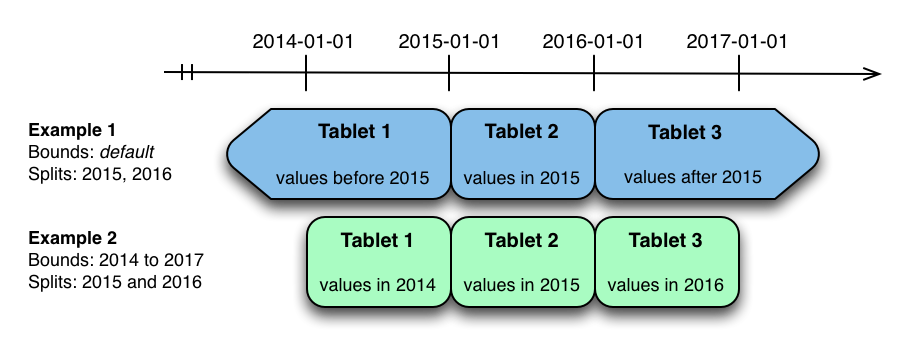
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26CREATE TABLE cust_behavior_table ( id BIGINT, sku STRING, salary STRING, edu_level INT, usergender STRING, group STRING, city STRING, postcode STRING, last_purchase_price FLOAT, last_purchase_date BIGINT, category STRING, rating INT, fulfilled_date BIGINT, PRIMARY KEY (id, sku) ) PARTITION BY RANGE (sku) ( PARTITION VALUES < ‘g’, PARTITION ‘g’ <= VALUES < ‘o’, PARTITION ‘o’ <= VALUES < ‘u’, PARTITION ‘u’ <= VALUES ) STORED AS KUDU TBLPROPERTIES( ‘kudu.table_name’ = ‘cust_behavior_1 ‘,’kudu.master_addresses’ = ‘hadoop5:7051’);混合分区(hash + range)
在hash分区下产生range分区,分区数量是 hash分区 * range分区 数量
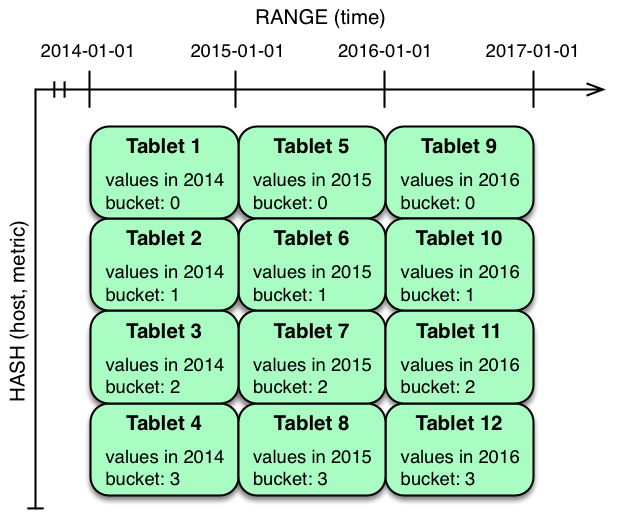
Partitioning Strategies
Strategy Writes Reads Tablet Growth range(time)✗ - all writes go to latest partition ✓ - time-bounded scans can be pruned ✓ - new tablets can be added for future time periods hash(host, metric)✓ - writes are spread evenly among tablets ✓ - scans on specific hosts and metrics can be pruned ✗ - tablets could grow too large 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28CREATE TABLE cust_behavior_1 ( id BIGINT, sku STRING, salary STRING, edu_level INT, usergender STRING, group STRING, city STRING, postcode STRING, last_purchase_price FLOAT, last_purchase_date BIGINT, category STRING, rating INT, fulfilled_date BIGINT, PRIMARY KEY (id, sku) ) PARTITION BY HASH (id) PARTITIONS 4, RANGE (sku) ( PARTITION VALUES < ‘g’, PARTITION ‘g’ <= VALUES < ‘o’, PARTITION ‘o’ <= VALUES < ‘u’, PARTITION ‘u’ <= VALUES ) STORED AS KUDU TBLPROPERTIES( ‘kudu.table_name’ = ‘cust_behavior_1 ‘,’kudu.master_addresses’ = ‘hadoop5:7051’);混合分区 (hash + hash)
hash + hash
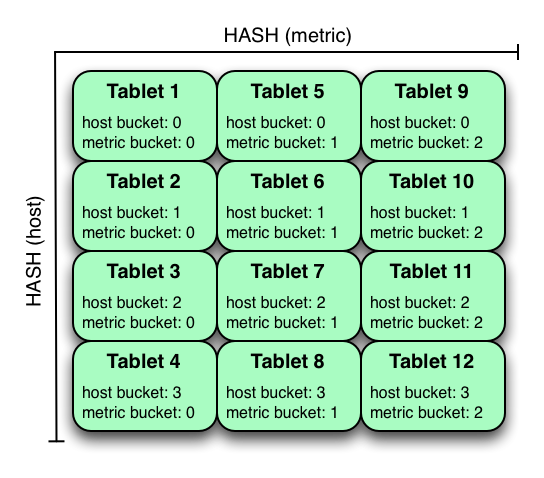
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22CREATE TABLE cust_behavior_1 ( id BIGINT, sku STRING, salary STRING, edu_level INT, usergender STRING, group STRING, city STRING, postcode STRING, last_purchase_price FLOAT, last_purchase_date BIGINT, category STRING, rating INT, fulfilled_date BIGINT, PRIMARY KEY (id, sku) ) PARTITION BY HASH (id) PARTITIONS 4, HASH (id) PARTITIONS 4 STORED AS KUDU TBLPROPERTIES( ‘kudu.table_name’ = ‘cust_behavior_1 ‘,’kudu.master_addresses’ = ‘hadoop5:7051’);
kudu表限制
表列数别太多
列数量不要超过300个
字段内容别太大
单个字段内容不要超过 64KB
行数据大小
理论上 64KB * 300, 建议不要超过这个理论值.
有效标识
表列明/字段名 必须为UTF-8格式且大小不能超过256bytes
主键不可变
Kudu不允许您在创建表后更改行中主键内容
主键列不允许变更
Kudu不允许您在创建表后更改主键列
分区可修改,但分区方式不可修改
除了添加或删除范围分区之外,Kudu不允许您在创建后更改表的分区方式
表类型不允许变更
Kudu不允许更改列的类型。
分区拆分合并
创建表后,无法拆分或合并分区。
优化
- 对于大型表格,如事实表,目标是在集群中拥有核心数量的 tablets 。
- 对于小型表格(如维度表),目标是足够数量的 tablets ,每个 tablets 的大小至少为 1 GB 。